Many recent models aim to be “generalist” systems that can perform pretty much any task we ask them to. At the same time, specializing a given model through parameter-efficient fine-tuning (PEFT) has become a common way to improve its capabilities, often on a specific task or domain. In addition, the “modules” produced via PEFT are cheap to share, which has led to the availability of a huge number of modules for popular pre-trained models like LLaMA and Stable Diffusion. The development, sharing, and proliferation of PEFT modules leads to a tantalizing question: Is there a way to recycle these modules to improve the zero-shot generalization of the base model (i.e., make it more competent at performing a wider range of tasks)?
We might formalize this question with the following setting:
- We want to recycle the PEFT modules that have been shared by individual contributors that aim to specialize or expand the capabilities of a given base model.
- The contributors generally don't share their data.
- We'd like to avoid asking the contributors to do a lot of extra work beyond training the PEFT module.
- Our goal is to improve the zero-shot generalization capabilities of the base model (this excludes methods that rely on a task-specific labeled dataset like AdapterFusion, LoraHub, and π-Tuning).
A class of techniques that satisfy this problem setting are “model routers” which aim to choose which model to route a given query to. Systems that fall into this category include LlamaIndex, Airoboros, Martian, and OpenRouter. Approaches to building such a router include asking a generalist LM which model to use (as (likely) done in most of the aforementioned systems), training a classifier to predict which model would be best (as done by Lu et al. 2023 and Shnitzer et al. 2023, or comparing an embedding of the query to embeddings of the datapoints used to train each model (as done by Jang et al. 2023, Belofsky 2023, and Maxine's MoLora).
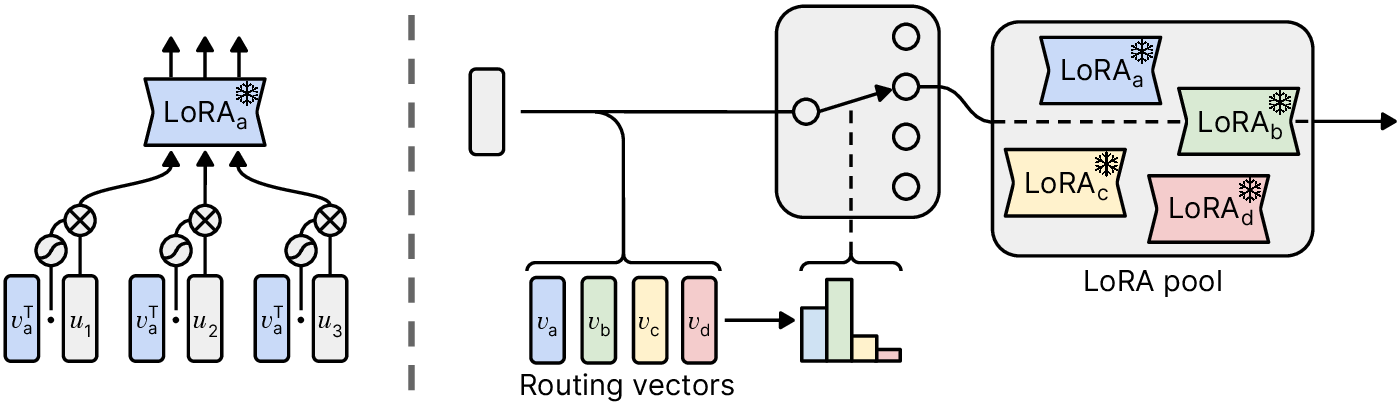
Note that many PEFT methods (like the ubiquitous LoRA) update a model by introducing many small modules throughout the model (a low-rank update module at each linear layer in the case of LoRA). All of the aforementioned approaches route the entirety of a query to a single model. What if we instead took inspiration from mixture-of-experts style models and chose a different module at each layer and for each sequence position? We might intuitively hope that this would allow the model to compose different skills by processing each token differently in different parts of the model.
My group started working on this problem over a year ago. It turns out that focusing on zero-shot generalization, assuming that we don't have access to the contributor's data, and trying to avoid as much additional work as possible makes things particularly challenging. I'm happy to say we've just posted a paper on arXiv that describes a method that fits our goals. Notably, it outperforms prior “model routers” and can even match or outperform explicit multitask learning in some cases!
We call the method “Post-Hoc Adaptive Tokenwise Gating Over an Ocean of Specialized Experts”, or PHATGOOSE.1 PHATGOOSE works by asking the contributors to perform an additional cheap training stage after they perform PEFT on their dataset. Specifically, the contributor freezes all of the model's parameters (including the new PEFT module parameters) and trains a sigmoid gate in front of each module that determines whether a given activation should be fed into the module. After training and collecting all of the PEFT modules and their gates, PHATGOOSE routes an activation among modules at a given layer by combining all of the sigmoid gate parameters to create a standard top-\(k\) router (as commonly used in mixture-of-expert-style models).
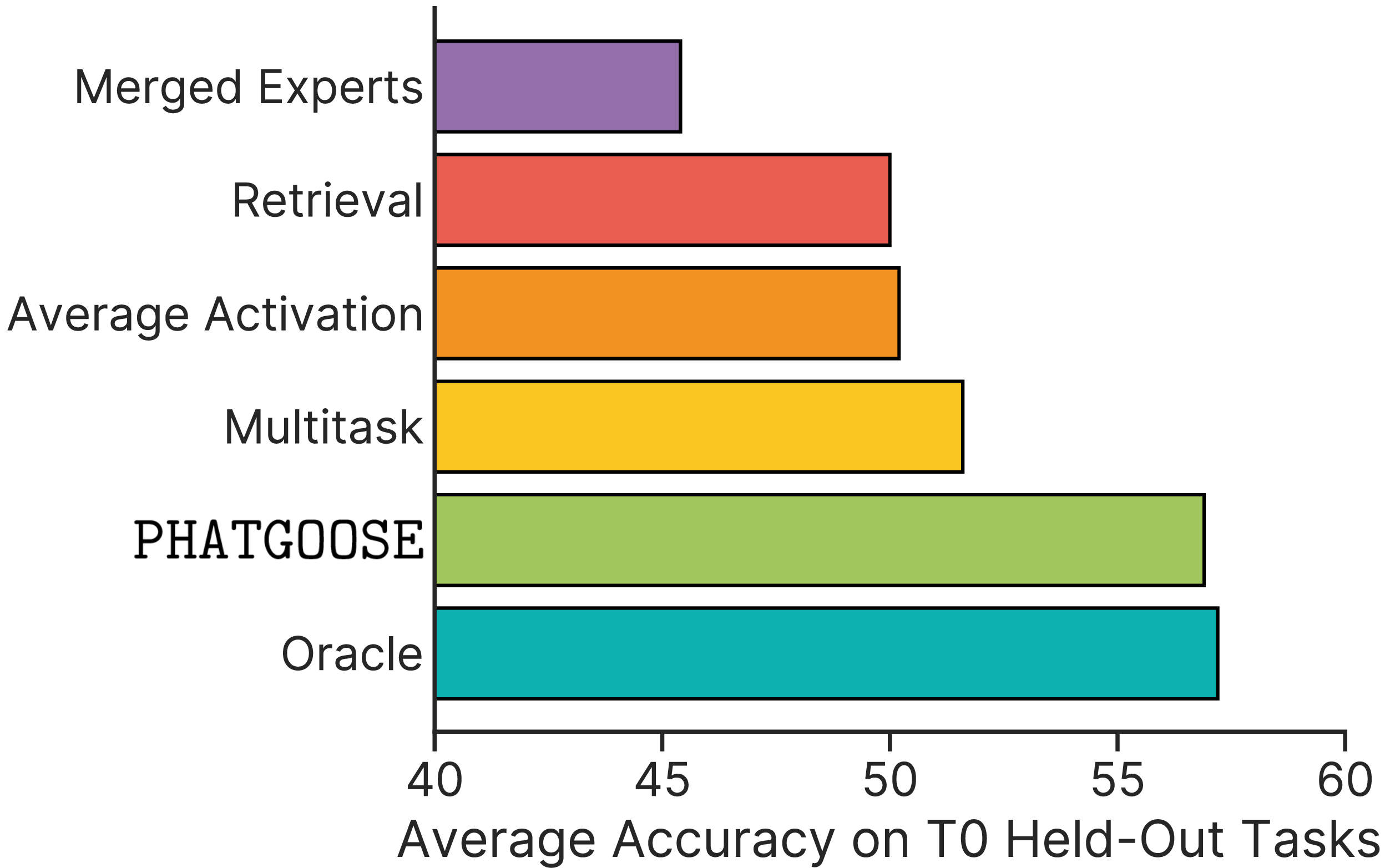
We benchmarked PHATGOOSE against prior methods that route among models and/or recycle specialized PEFT modules. When routing among modules specialized to the datasets used to train T0 and evaluating zero-shot generalization on T0's held-out datasets, PHATGOOSE not only outperforms prior routing and recycling methods but also outperforms multitask training (which requires simultaneous data access) and nearly matches an oracle routing baseline.
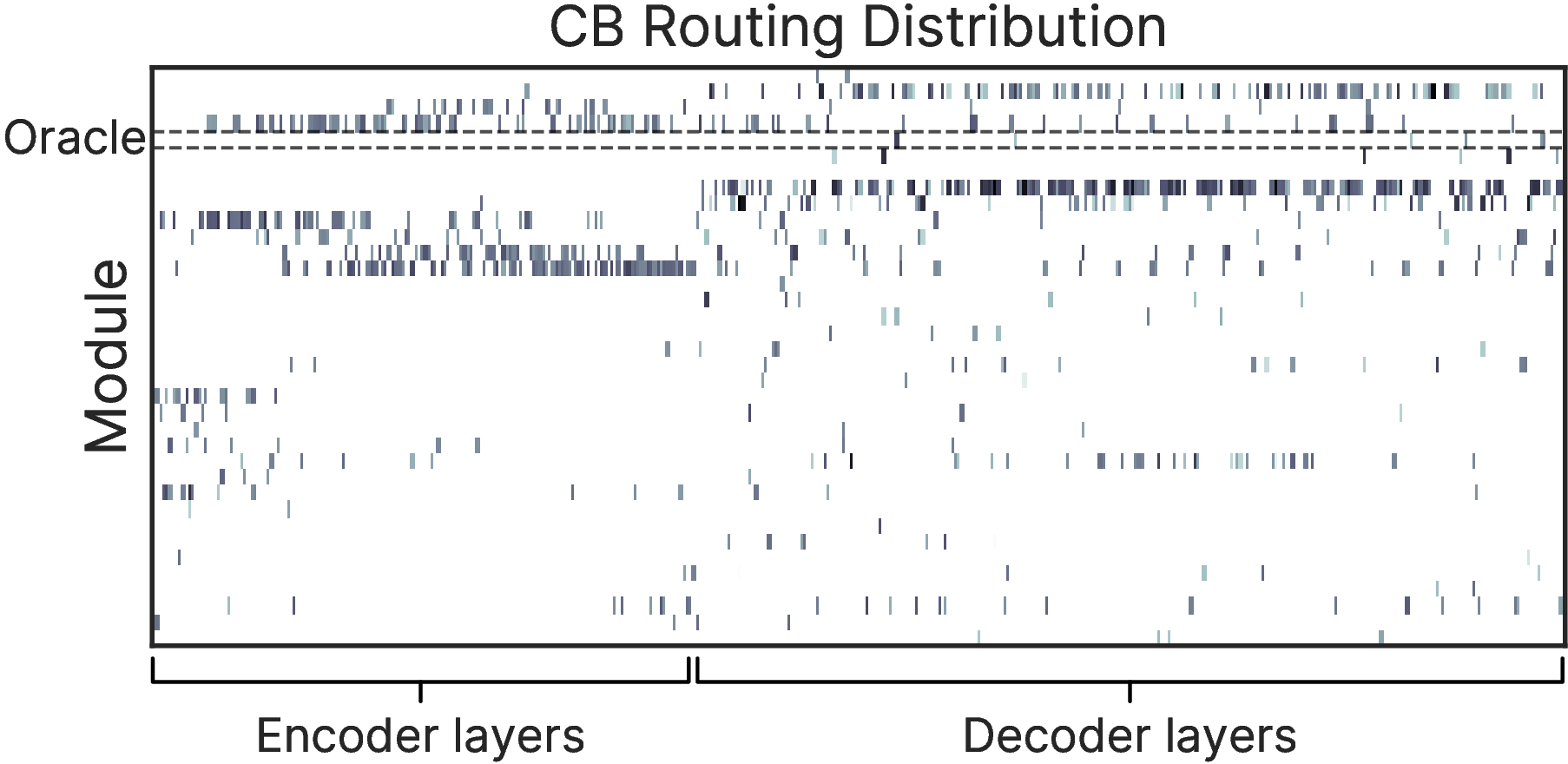
We also evaluated PHATGOOSE's performance on BIG-Bench Hard and Lite, using the T0 held-in expert pool as well as a large expert pool built from the datasets in the FLAN collection. In those settings, PHATGOOSE's performance was not as stellar, but it nevertheless consistently outperformed all other methods that recycle and/or route among experts. One interesting thing that we found was that PHATGOOSE doesn't just route to the single “best” expert for a particular dataset and that it did indeed choose modules from different datasets at different layers and sequence positions.
Overall, I'm excited about making progress on the “expert recycling and routing” problem. The biggest limitation of PHATGOOSE is that it requires contributors to perform the additional step of training the gate. While computationally inexpensive, most people uploading PEFT modules aren't performing this step. I'm optimistic that we'll be able to make additional progress by instead allowing whatever entity “collects” the PEFT modules to perform some additional training on their own data (which may be disjoint from the data used to train the modules). I'm also excited about applying these ideas in more realistic settings beyond academic benchmarks — for example, by recycling the many LoRAs that have been built on top of open LMs to build even more performant models. On the whole, I think our work validates and motivates a promising paradigm for decentralized development of generalist models.