I've spent the past year doing the Google Brain Residency Program. It's been a great opportunity for the first year out of my PhD, and in this blog post I'll describe what the residency was like, what I worked on while here, and what I'm doing next.
The Residency
Throughout the year I've had a lot of people ask me what the residency actually is, since this is the first year Brain is running it. The most accurate description I've heard is that it's like spending a year in a PhD, except you're at Brain, not at a university. If you're new to machine learning, it might be like the first year of a PhD (except without any classes!). If you already have a lot of experience in ML, doing research, writing papers, etc., it may be more like one of the later years of a PhD. That said, if you do the residency for four or five years you won't be able to make people call you “doctor”.
I think this is an apt description because my day-to-day routine and responsibilities felt pretty unchanged compared to what I was doing during my PhD. Specifically, I'd normally spend an hour or two each morning reading papers, then I'd spend the day writing code to run experiments. From time to time, I'd attend talks by Brain researchers or people visiting. I had various people serving as my “advisor”, who I'd report my research progress to and bounce ideas off of. And, as usual, around paper deadlines I'd often be trying to cram my experimental results into the page limit for some conference or another.
Of course, there have been some substantial differences too, mostly stemming from the fact that Brain is a very large research lab (hundreds of people), whereas most academic labs are considerably smaller. What this means in practice is that if you have a question about some specific research topic, there's probably someone at Brain who has worked on it, or more concretely if you're reading some random recent machine learning paper there's a good chance one of the authors is sitting within a few hundred feet from you. Also, it makes for many more opportunities for collaboration - maybe too many! I had never had to turn down/put off working on promising research with smart people before coming to Brain.
Another significant difference is that you have a pretty crazy amount of computation at your disposal. It is generally not a big deal to spin up experiments on dozens or even hundreds of GPUs. This does have a concrete effect on the type of work you do - there's a lot more room to try lots of different ideas, hyperparameter configurations, etc. It also means you can be a bit more careless about getting everything just right/highly optimized before kicking off an experiment, for better or worse. I remember during my PhD I spent a considerable amount of time benchmarking different Theano ops so that I could squeeze out maximal performance from my single GPU. At Google, there's much less emphasis on fine-grain efficiency; instead, the focus is on scaling up.
What I worked on
My goals for the residency were basically 1. do foundational (as opposed to application-specific) ML research, 2. learn stuff, 3. take advantage of the fact that I was at Brain. My background coming in mostly involved machine learning models for sequential data (my PhD was mostly focused on ML applied to music), so this gave me a heavy bias when choosing which problems I was going to work on (though I did get a chance to branch out a bit).
Subsampling Sequences
My first project was an attempt to create a model which was able to discover hierarchical structure in sequences on its own. Many sequences can be naturally decomposed into a hierarchy (e.g. document → paragraphs → sentences → words → characters), so we might expect a model which can discover this hierarchy to be particularly powerful or at least more easily interpretable. To attack this problem, I decided to focus on a relatively simple mechanism, which can be described as follows: Say you have an input sequence, and you want to construct a shorter output sequence by making a binary yes/no decision as to whether you're going to include each entry of the input sequence in the output sequence. Effectively, you're just “subsampling” the input sequence to produce a new shorter sequence. The decision of whether to include each input sequence entry in the output can be adaptive, i.e. based on the input sequence itself. Here's a diagram which illustrates this idea:
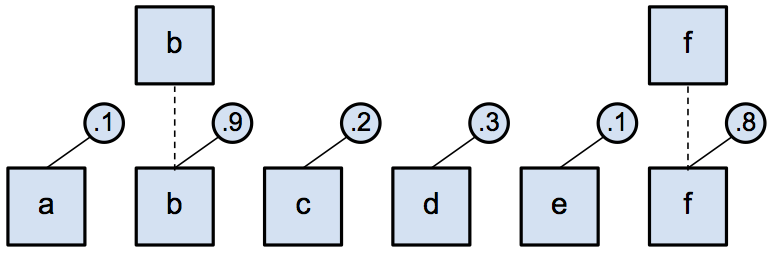
You can imagine that processing a sequence with an RNN and applying this “subsampling mechanism” multiple times might encourage the model to learn a hierarchical representation, where you can think of each element in each successively shorter sequence as representing a coarser concept present in the input sequence. Fortunately, it's possible to derive an expression for the probability that a given input sequence element is included in the output, so you can train a model using this mechanism with standard backpropagation. Unfortunately, I wasn't able to get good results with this approach on any tasks except for a simple toy problem. For example, I was only able to get a model using this mechanism to achieve a ~30% phone error rate on TIMIT (state of the art is around 17%). I nevertheless wrote up the idea in an ICLR workshop extended abstract [raffel2017a] to make people aware that training a subsampling mechanism in expectation is possible.
Monotonic Attention
One reason I thought the subsampling mechanism might not be working well in practice was that the “subsampling probabilities” had to be computed all at once and prior to producing any output. To remedy this, I made a connection to sequence-to-sequence models with an attention mechanism, which can transduce an input sequence into a new output sequence. As each element in the output is generated, it's allowed to “attend” back to entries in the input which helps it more directly condition the output generation process. While attention has proven extremely effective, its “vanilla” form has a few drawbacks: First, these models can't be used online - that is, they can't produce the output as the input sequence is being generated; and second, they have a quadratic-time complexity, because for each element of the output sequence the model must re-process the entire input sequence. However, by replacing standard attention with the subsampling mechanism we can actually get an online and linear-time sequence-to-sequence model. This gives us a sort of “monotonic attention”, where once the model attends to a given entry in the input, it can't attend to anything that came before it in subsequent output timesteps. As with the subsampling mechanism, there is a simple way to train this mechanism in expectation without resorting to gradient estimation. Schematically, monotonic attention looks something like the following:
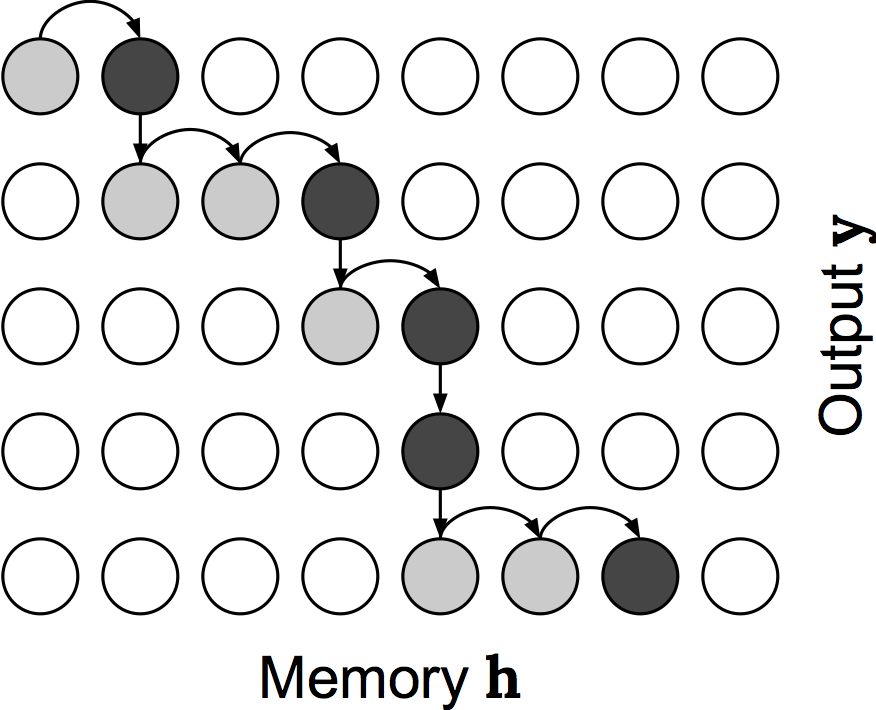
One nice thing about this project was that I was able to leverage existing expertise and codebases within Google to accelerate experiments. Unsurprisingly, there were many teams and projects in Google using sequence-to-sequence models with attention, and I had formulated this “monotonic attention” in such a way that hot-swapping it with standard attention was relatively straightforward. As a result, I implemented this approach in four different codebases; this breadth gave me a lot of insight into whether the model was applicable across tasks. The culmination of the project was an ICML paper [raffel2017b]. I also wrote up a more in-depth blog post about it here.
Hard Alignments with RL
An unsurprising (but still unexpected to me) result of working at a lab as large as Brain (or a company as big as Google/Alphabet) is that there can be multiple groups of people working on very similar ideas in parallel. This was the case for the monotonic attention work - some of my fellow residents and other colleagues at Brain were simultaneously working on a very similar model. However, instead of training in expectation with backpropagation, they instead focused on training the model with hard alignments (i.e. keeping the decision of “what to attend to” discrete). This precludes the use of backpropagation, so they carried out a thorough investigation of gradient estimation techniques (REINFORCE [williams1992], NVIL [mnih2014], VIMCO [mnih2016]) to use instead. The nice thing about this approach is that it makes the training and test-time model behavior the same, which among other things means that training is linear-time too. The difficult part is that variance of the gradient estimates can make training hard to get right without some care.
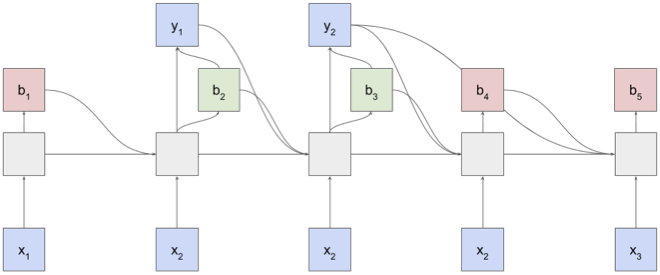
In the beginning, we mostly shared results and insight at a high-level, but eventually I ended up trying out their idea on a sentence summarization benchmark I had been working with. This was mainly to see whether it worked in a setting other than speech recognition, which had been their primary testbed. Unfortunately it wasn't able to beat a simple attention-free sequence-to-sequence baseline, which suggested that the model was not really taking advantage of the attention mechanism. This could be at least in part because getting the model to work on speech recognition required some regularization which didn't generalize well to text data. Despite the negative result, this gave us some interesting insight into the importance of the different methods being used to train the model. After running this experiment, I mostly helped out on a high-level again, and they've recently posted a nice paper on arXiv about this approach [lawson2017].
Direct Feedback Alignment
Sometime during my residency, I was chatting with my fellow resident Cinjon about synthetic gradients [jaderberg2016] when Ben (then an intern) came up and said “Oh, you think synthetic gradients are weird? Just wait until you hear about direct feedback alignment.” Sure enough, direct feedback alignment (DFA) [nokland2016] is a pretty weird idea: In normal backpropagation, the network's “error” (gradient of loss w.r.t. output nonlinearity pre-activations) is backpropagated to earlier layers via multiplication against each layer's weight matrix, transposed. In DFA, we instead take the network's error and multiply it against a fixed random matrix to compute the updates for each layer's parameters. Surprisingly, this seems to work ok.
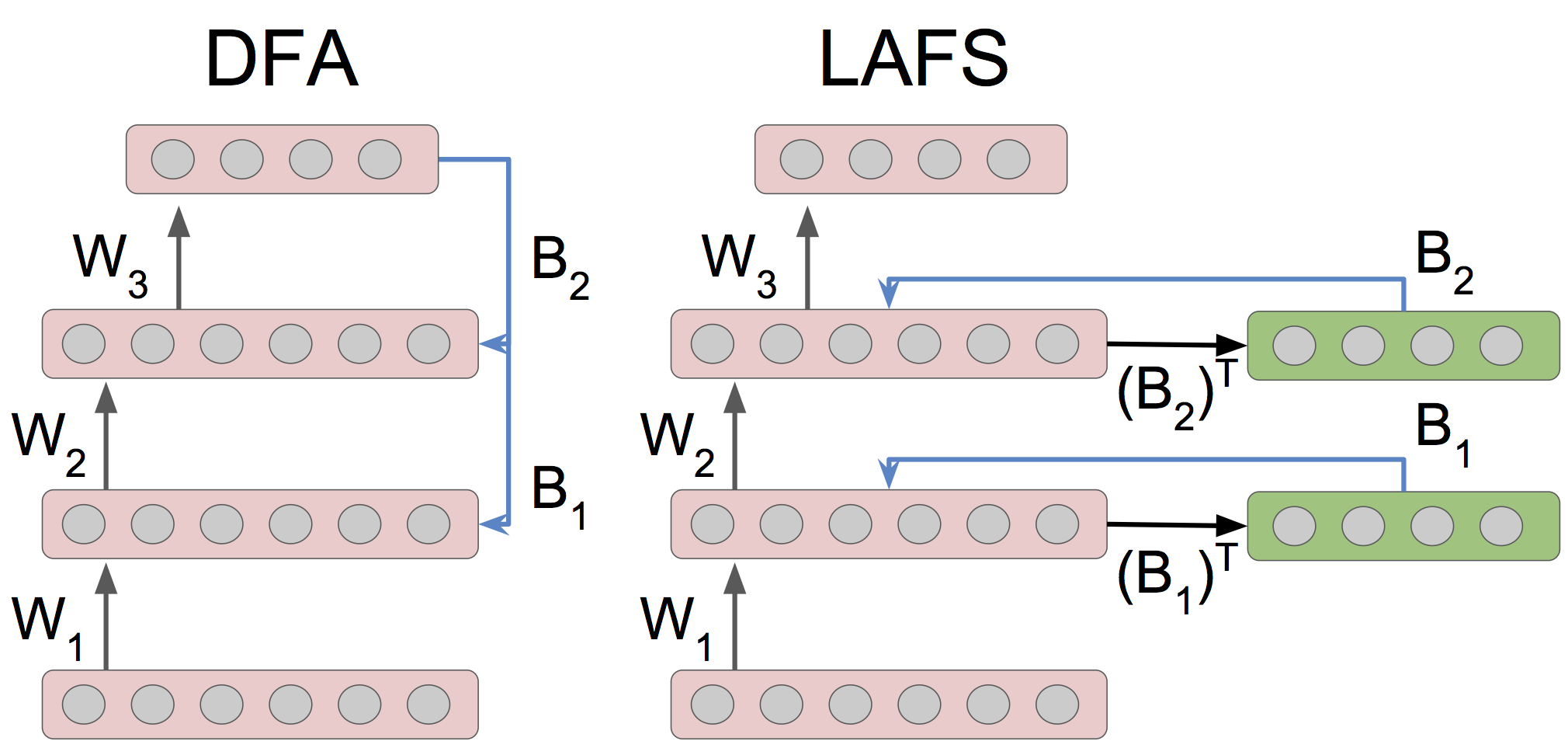
Reading this paper and trying to understand why DFA works led to some long discussions with Brain team members, some people at DeepMind, and the paper's author. The eventual culmination of all of this was an ICLR extended abstract [gilmer2017a], where we show that DFA can be seen as extremely similar to layer-wise training, where the layer-wise predictions are made through fixed random matrices. The tl;dr version being that, under this view, it's not that surprising that DFA works!
Magenta
A nice thing about working at Brain for me personally was that, while I could learn about new research areas and do foundational ML research, there was a group within Brain which was partially focused on music: Magenta. I never did substantial work under the Magenta umbrella, but they were nice enough to let me come to their meetings and even asked me for my opinion on different research ideas from time to time. I also got the chance to go to Moogfest to represent Magenta, where I helped lead a tutorial on some of the tools they've developed.
What I'm Doing Next
My initial post-PhD plan was (fittingly) to do a postdoc. After deciding to do the residency instead, I still planned to do a postdoc after the residency. A postdoc sounds really nice to me, in terms of where I'm at in my research career - I still want good top-down advice from an advisor, but I've also really enjoyed my mentorship opportunities in the past, and a postdoc seems like an ideal combination of these dynamics. But, I've ultimately decided to stay at Brain as a research scientist (and fortunately Google is on board with this decision). Here's why: I think if you asked your average ML researcher to describe their ideal research lab, they'd say something like “I'd like to be able to work on whatever I want, be surrounded by smart people, share my results freely, and have effectively unlimited resources.” Incidentally, I think you could describe Brain this way.
I honestly don't know of a lab anywhere where researchers have the same freedom that they do at Brain; I think I realized this when I was talking to my fellow resident Sam and he said something along the lines of “look, I just wrote a paper on chemistry [gilmer2017b]. What ML-focused research labs would let me do something like that?” As far as I can tell, researchers at Brain are never required, or even asked, to work on research that would benefit some specific product (though I get the impression it wouldn't hurt if they did).
In terms of colleagues, as I mentioned above you are basically surrounded by leading ML researchers. In analogy with the postdoc, a new crop of residents has just arrived and there are always interns around, which provides excellent potential mentorship opportunities. I also have come to realize that a huge part of a lab's culture comes from its leadership, and I think Brain's great culture is largely thanks to this. The senior staff at Brain are uniformly approachable, friendly, and sharing-focused. Of course, the more junior people are also extremely knowledgeable and hard-working.
Brain also has a comparatively strong bias towards sharing work - in particular, I think the fact that TensorFlow is open-source and is developed here pushes for this a lot. At an academic lab, publishing and sharing is basically your job description; the exact same is true for research scientists at Brain. In other words, there is no discernible difference in my job description and deliverables compared to (for example) a postdoc's, except that I'm not going to be teaching any formal courses.
So, I'm staying at Brain. Concretely, I'm working in Ian Goodfellow's group, which means I'll be devoting a lot of my time to ML security, adversarial training, and un/semi-supervised learning. I'm looking forward to being directly supervised by an expert, while having the opportunity to mentor residents and interns who want to work on projects in this domain. Of course, I'll probably continue to devote a bit of time to ML models for sequential data and music, because old habits die hard!